Watch the full video from the AI Engineer summit here.
How is the research agent different from the normal flow?
- It’s an asynchronous feature
- It’s not helpful for most of the common queries asked to Gemini
- It’s to answer more specific questions
- Handles long outputs
UX solution
Gemini starts off with making a research plan:
- Transparency between agent and user
- User can edit the plan → steering the agent
Gemini shares the list of websites that is surfs through while doing it’s research
Gemini creates an artifact, which users can read and ask questions about in real time while the report is there. All the stuff cited stays in memory of the agent so that users can ask about them and it could look up there
Challenges
- Long running tasks
- Needs to be an asynchronous system
- The user needs to be aware of once the research is done
- Resistant to failures of intermediate steps during long running tasks to not drop the results of a long running research
- Needs to be an asynchronous system
- Multi step planning
- The agent needs to react to the information found and decide what needs further exploration / verification.
- Exploration and inference budget trade off. You can explore more, hence increase your chances of finding the gold information, but you have to take into account the timing that it takes to get that information – users can’t wait for too long either.
- Fragmented web
- Websites are noisy, they have a lot of unnecessary information. Documents and files are represented differently and have to be properly parsed to get the information across. There are access and rights issues. Partially available information.
- Context management
- Balancing between using all the information in the context, and efficiency of the LLM – it has a limited context size.
- Sharing research and output between turns when relevant. If you break the context into multiple parts, you need to manage when some parts are relevant and can be considered together.
Multi step planning
- Model continuously reasons over which sub problems has completed and which ones it still has to work on
- Figure out which of the problems can be handled in parallel and which ones can be done sequentially
- There are results which provide partial information, the results can satisfy one of the user’s request but nothing is said about the other constraint: the model has to notice this, and plan to resolve this ambiguity (does the result satisfy the second constraint)
- Information is spread out: to get the complete understanding multiple sources have to be joined together to figure out what the full thing is
- Entity resolution: there are results which come from different sources and the model has to be able to reason that these two entities are in-fact the same one
Web is fragmented
- Layouts are different in the web
- There needs to be a robust way to extract information from pages
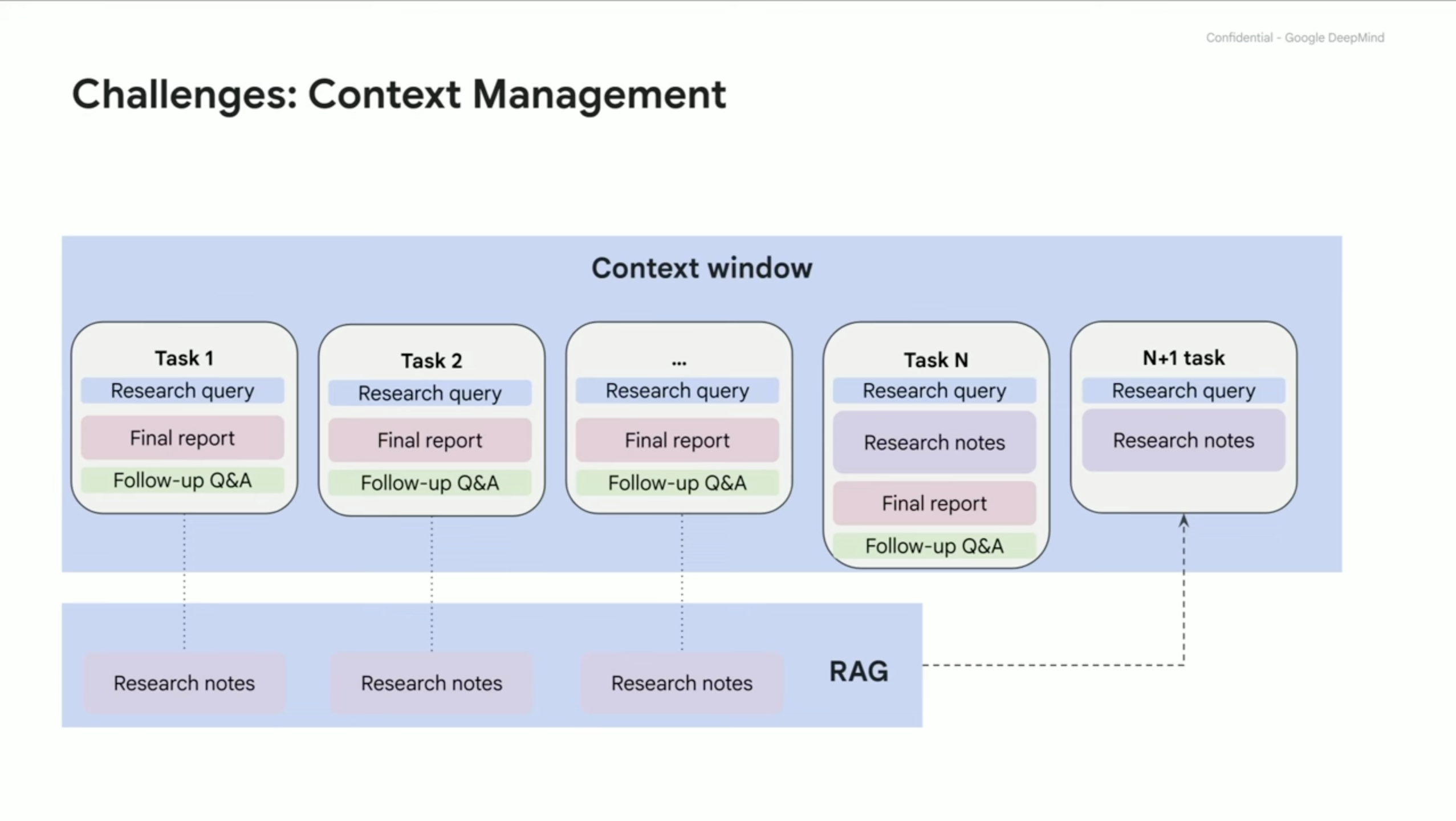
Context Management
- The context grows quickly, that has to be managed
- User’s have follow up questions which cause more pressure on the context
- There are many ways to tackle this challenge with various trade-offs
One of the solutions if the to have a context window. As the context grows with user’s tasks, after every task the model stores the knowledge in a form of research notes, which are placed into RAG (acting like memory basically). And in the future the model is able to retrieve the information discussed earlier although it is condensed.
Future of deep research
Now it can only search the web, and it’s only text-in-text out
- it doesn’t support image retrieval/injection into it’s text
Future:
- be able to not just ingest text and synthesize new one, but actually think about “so what” aspect of it
- something that can read a lot of papers form hypothesis, find patterns in methods used and come up with new hypothesis to explore
- something just smart ≠ useful to someone; different users with different backgrounds should get different results (bankers, scientists, politicians view every topic differently)
- combine multiple domains together, web research with coding, data science, image/video generation