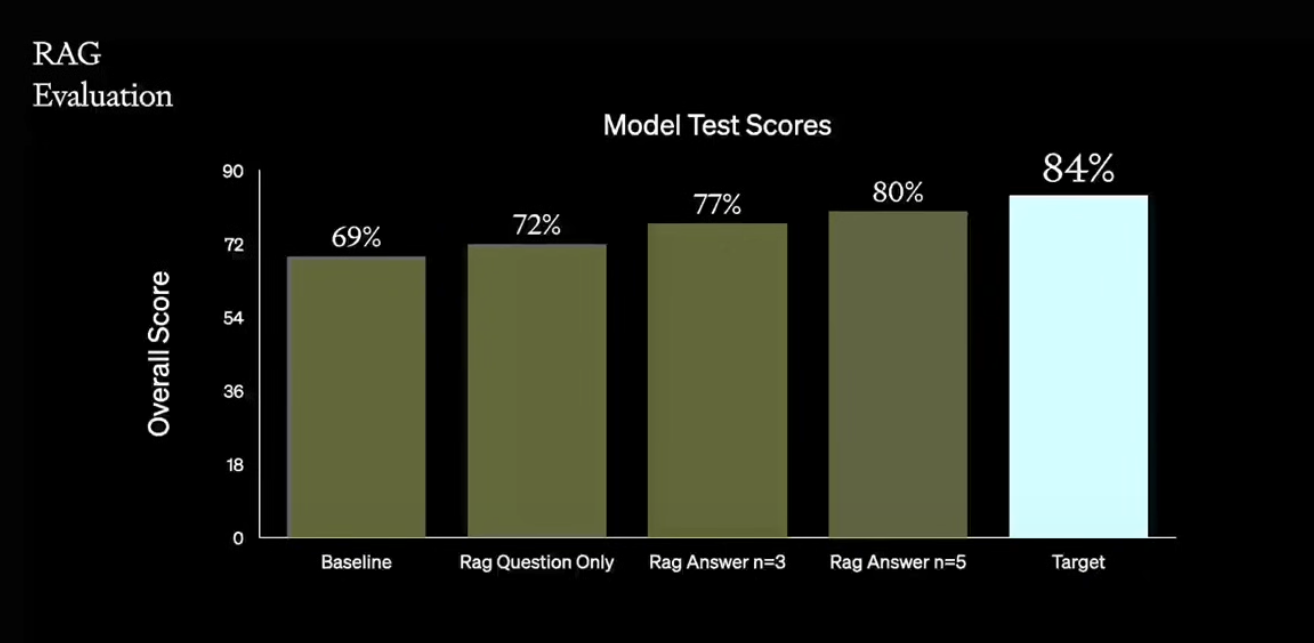
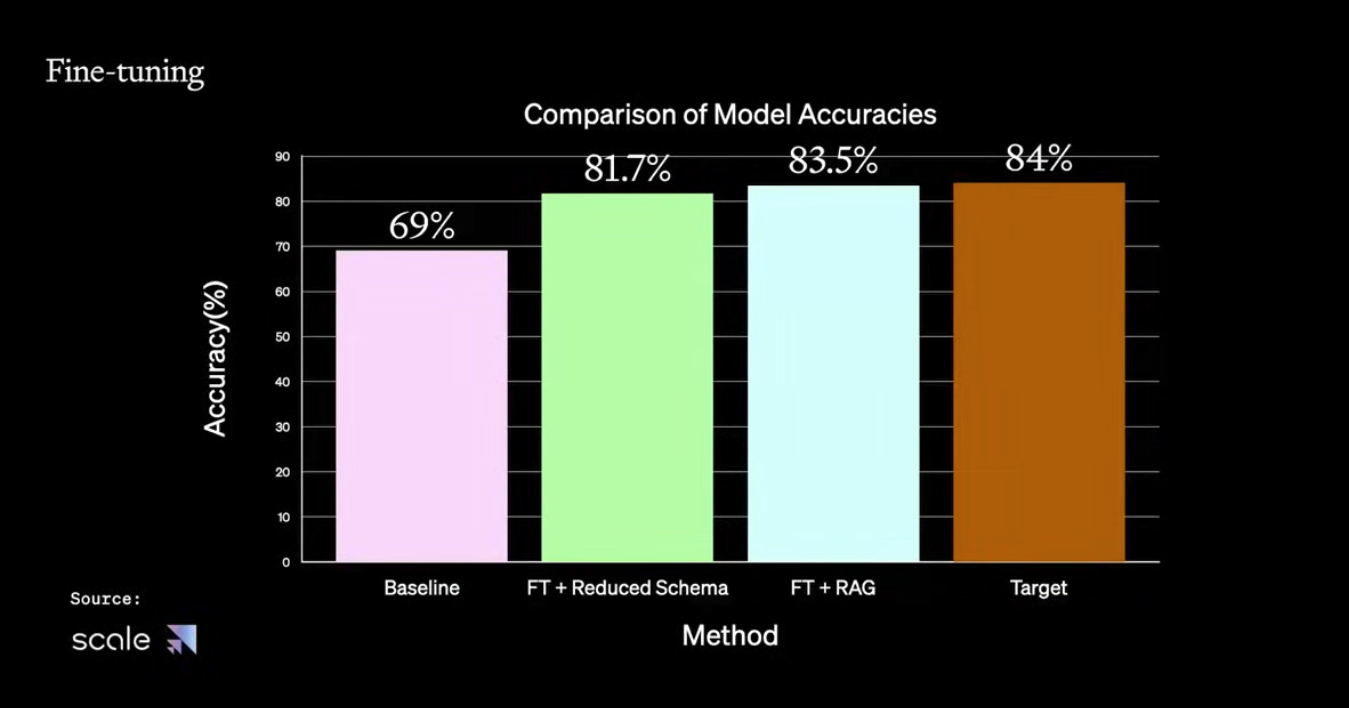
Watch full video from the OpenAI team here.
Optimizing LLMs is still hard, no matter how many frameworks there are.
Main difficulties:
- Extracting signal from the noise is hard
- Performance can be best abstract and difficult to measure
- When to use what optimization
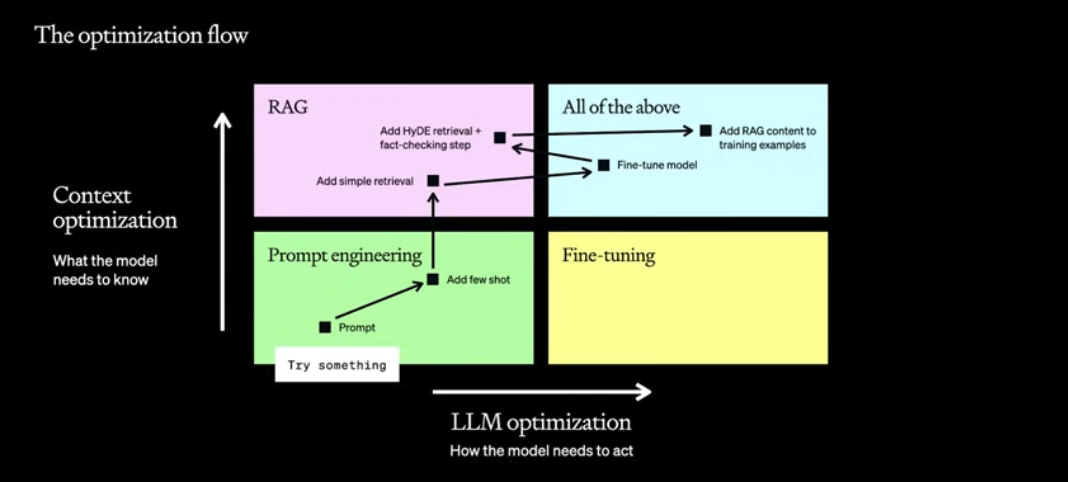
The optimization flow
There are two axis along which we can optimize the models:
- Context optimization: what the model needs to know
- LLM optimization: How the model needs to act
The path isn’t necessarily linear, you usually start off with prompt engineering, use few-shot examples, then you notice the issue is in knowledge – so you add retrieval, then the format of answering isn’t right – so you do fine-tuning, then you go back and improve retrieval with HyDE and fact-checking and so on…
RAG and fine-tuning solve inherently different problems. If you imagine that the model has short and long term memory-loss, then RAG solves the short and fine-tune solves the long.
- RAG – when the model needs specific information to answer questions
- Fine-tune – when the model needs to follow a structure, style, format Both approaches are additive, sometimes you might need both for the most optimal performance.
Prompt engineering
Start with:
- Writing clear instructions
- Split complex tasks into smaller subtasks
- Give GPTs time to “think”
- Like ReAct
- Test changes systematically
Extend to:
- Providing reference text
- Use external tools
Good for:
- Testing and learning early
- With evaluation, can be set up as a baseline for further optimization
Not good for:
- Introducing new information
- Models can hallucinate
- Reliably replicate a complex style/method
- For example, can’t learn a new programming language
- Minimizing token usage
- Providing instructions increases the number of tokens
Retrieval augmented generation
Giving model access to domain specific knowledge. There are many ways to do it. Usually, some documents are embedded into a knowledge base. Afterwards, a user can ask an agent a question and the agent will be able to retrieve relevant documents from the knowledge base and give a relevant answer.
Good for
- Introducing new information to the model to update its knowledge
- Reducing hallucinations be controlling the content
- Give an instruction to only use the knowledge provided to do the generation
Not good for:
- Embedding understanding of a broad domain
- The model isn’t learning this information, it uses what it has at hand to generate a response
- Teaching the model to learn a new language, format or style
- This is more of fine-tuning
- Reducing token usage
- This is gonna use much more tokens
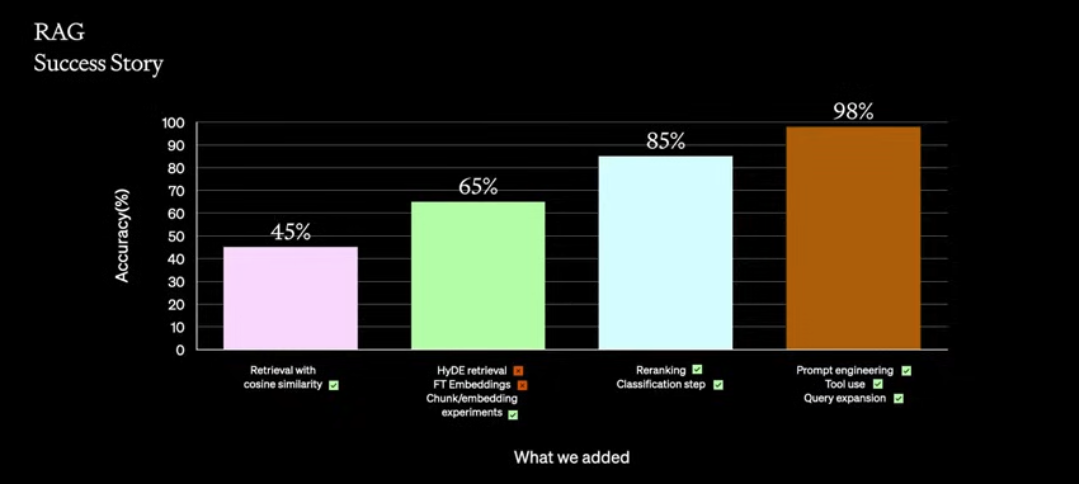 The methods OpenAI team used for a customer and what performance boosts they gave. Ones with the checkmarks made it to production.
The methods OpenAI team used for a customer and what performance boosts they gave. Ones with the checkmarks made it to production.
Methods that they used:
- Basic retrieval using cosine similarity on embeddings
- Hypothetical Document Embeddings (HyDE)
- Generate hypothetical document and then use it to retrieve similar real ones
- Fine-tuning the embeddings
- Okay in improving accuracy, but
- Turns out to be impractically expensive with time and money
- Chunking/ embedding experiments
- Trying different sizes of chunks for embeddings
- Reranking to choose better from the retrieved content
- Use cross encoder to compare the query and retrieved result to see if any are more relevant
- Use rules, for example for research more recent articles could be preferred
- Classification of domain, for conditional prompts
- Let the model classify what case it is and then based on that add additional prompts
- More prompt engineering
- Observe where the model is making mistakes and improve there
- Tools for structured data questions
- Query expansion
- Users ask a lot of questions in one, you split them, process them in parallel and combine join back to one
RAG is about context optimization
There are two directions to improve with RAG, either you are
- Not giving it the right context or
- The model doesn’t know which of those context blocks is the right one
Personally, it reminds of the precision and recall problem
Warning about RAG
To prevent hallucinations, often, an instruction of sorts “use only the provided content as a source” is added. However, if the retrieval is poorly made – the LLM can use spurious results from the search which would lead to an incorrect answer.
By adding RAG, you add another axis of where stuff could go wrong. The LLM can make mistakes, and now there is search – which is an unsolved problem.
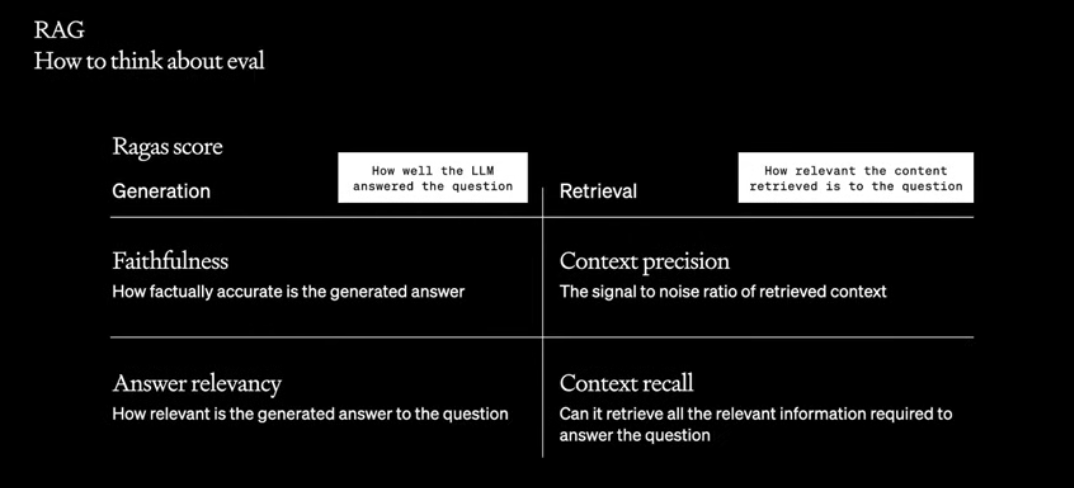
Evaluation RAG
Ragas score evaluates into two directions
Generation: How well the LLM answered the question
- Faithfulness – how factually accurate is the generated answer
- Basically check for hallucinations, how much is LLM not making up?
- Answer relevancy – how relevant is the generated answer to the question
- The answer can be factually correct, but totally irrelevant
Retrieval: How relevant the content retrieved is to the question
- Context precision – the signal to noise ratio of retrieved context
- Of the information that was retrieved, how much is actually relevant
- Technically we can give it a lot of content, but then the model can have a lost in the middle problem where it forgets things in the middle of the context and starts to hallucinate
- We want to increase this metric, partially because noice wastes tokens (hence money and space for actually relevant information)
- Can we get high quality answers why using less context
- Context recall – can it retrieve all the relevant information required to answer a question
- Is there information that was not retrieved, but was actually relevant?
- We want to increase this so that the information retrieved for the LLM is complete
- This metric shows if you need to do reranking, changing embeddings to surface more relevant content
Fine-tuning
Fine-tuning is when a trained model, is continuing the training on a smaller, domain-specific dataset to optimize for the model for a specific task
For an LLM, instead of explaining how you want the model to reply (prompt engineering) we fine-tune a model to output in that format. No need to provide examples.
Benefits:
- Improve model’s performance on a specific task
- During fine-tuning the model will see many more examples of how to do a task than wtih prompt engineering or few-shot learning
- Improve model efficiency
- Reduce the number of tokens needed to explain a specific task
- The model knows the pattern of the task, so you don’t need to explain it
- Distill the expertise of a large model into a smaller one
- Generate examples using a bigger smarter model and using that train a smaller one
- Reduce the number of tokens needed to explain a specific task
Good for
- Emphasizing knowledge that already exists in the model
- Customizing the structure or tone of responses
- Teaching a model very complex instructions
- You can just show much more
Bad for
- Adding new knowledge to the base model
- It doesn’t efficiently learn new information like this
- You are better off doing RAG
- Quickly iterating on a new use-case
- It takes time to create a dataset and time to get the training of the model right
- Slow feedback loop
Fine-tuning best practices
- Don’t start with fine-tuning: try prompt engineering and few-shot learning
- Establish a baseline: use it to compare your fine-tuned models to
- Quality over quantity: build small but high quality examples
- Datasets are difficult to build, but you also don’t need a HUGE amount of data, the model is pre-trained, what you do need are a few but high quality examples of expected behaviour
Warning about fine-tuning
During fine-tuning the model will learn to reflect the dataset that was used for training. It will reflect the type of language that is in the dataset.
A funny story mentioned was about a team fine-tuning GPT on their Slack messages to capture their tone of writing for blog posts. But when prompted to write a post, GPT said, “sure, I’ll work on that on Monday.”
Fine-tuning worked well, it reflected their writing style – but for Slack, and not their tone for the blog as the engineers expected.
What they should have done is fine-tuned on a small dataset an checked if the model is going in the right direction.
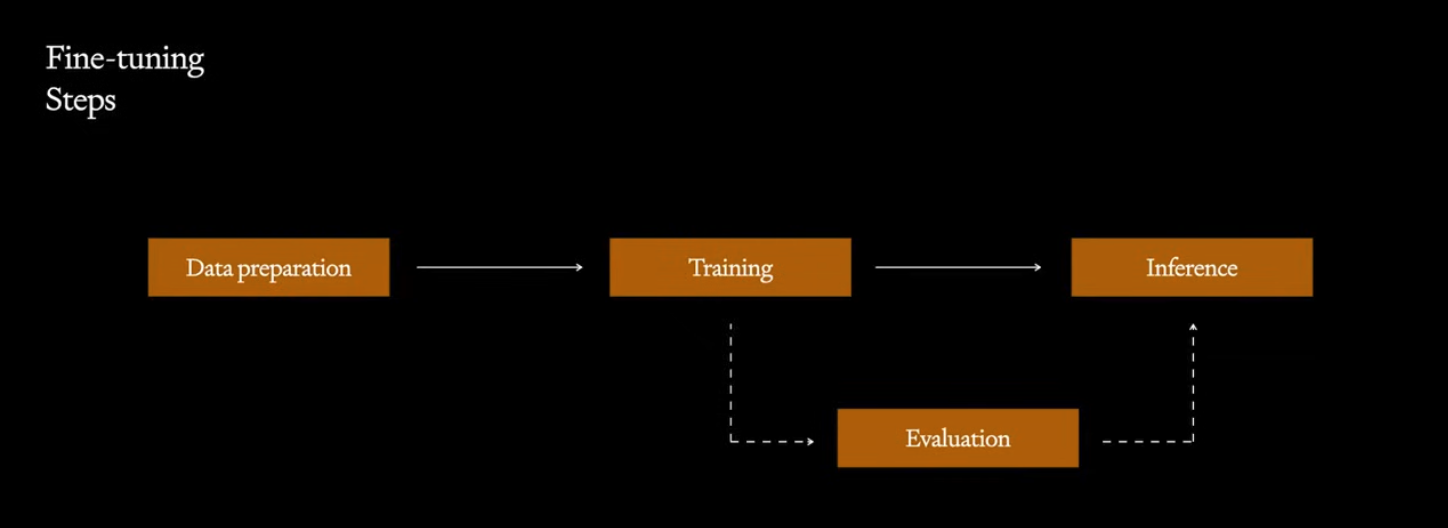
Steps to fine-tuning a model:
- Collecting the data, cleaning, validating, formatting it
- This is usually the most difficult part of the ML workflow
- Possible ways to acquire one could be: downloading from online, buy data, hiring labelers or distill it from a bigger model (if it’s allowed)
- Training
- if DIY, then you need GPUs, use a framework
- selecting hyperparameters
- understanding the loss function
- in this case, the loss function is a proxy for next token prediction
- improvements in loss might not correlate to with the downstream tasks
- Evaluation
- Have humans label how good results are
- Compare the results of two models against each other
- Have a bigger model evaluate the smaller one
- Inference
- Save the examples and results from production and go back to improve, ie feedback loop
Fine-tuning + RAG
Combining the two, brings the best of both worlds
- Fine-tuning the model to understand the complex instructions
- No more need to explain it, leading to…
- Minimizing prompt engineering tokens
- More space for retrieved context
- Use RAG to inject relevant knowledge into the context
- Model answers based on retrieved knowledge
Afterwards the team went through an example of how they optimized LLMs for SQL query generation based on the schema and question.