Watch the full video by Jerry Liu here.
The questions to the LLM can be of different types:
- very specific
- multi-part or something vague
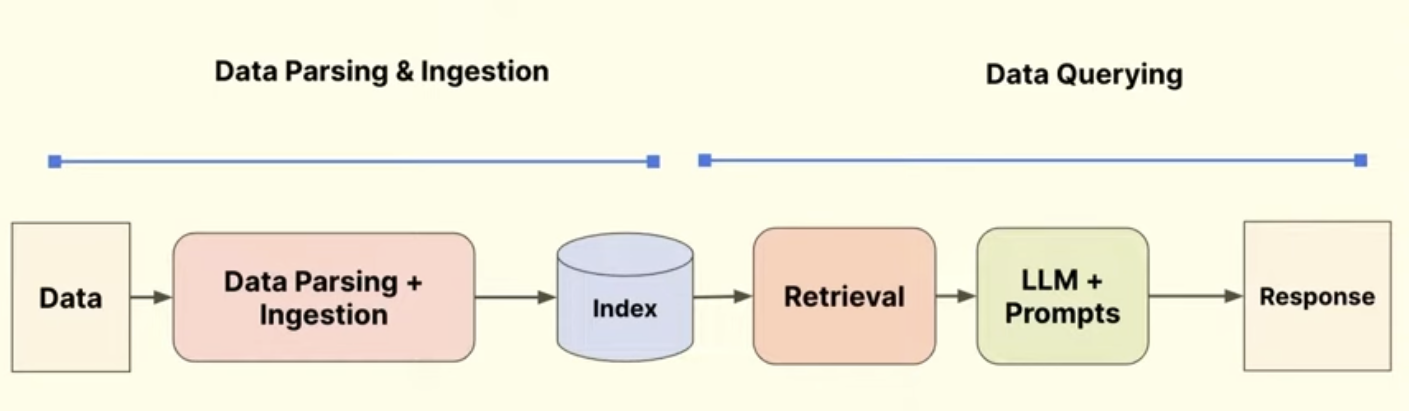
Retrieval Augmented Generation (RAG)
RAG pipeline consists of two parts:
- data parsing and ingestion
- data querying
Naive RAG – dump documents, chuck, embed, index, query, retrieve, slam all into context and produce a response
- ❇️ does really well with specific questions over small documents
- 🛑 fails at simple questions over complex data (images, tables, charts)
- 🛑 fails at simple questions over multiple documents
- 🛑 fails at complex questions
Goal: get high response quality from the questions asked
Naive RAG is just a fancy word for a search system, which can’t even answer to a lot of questions.
Improving Data Quality
RAG is only as good as the data in it – garbage in = garbage out
Data processing main components:
- Parsing
- Bad parsing produces garbage
- Badly formatted tables confuse LLMs
- Chunking
- Try preserving semantically similar content
- If a relevant paragraph, which has the answer was to be split in half then the first part would be retrieved, while not the second one because it didn’t have enough relevant content to be retrieved. Then the answer turns out incomplete.
- 5 Levels of Text Splitting
- A strong baseline for chunking is on page level, we as humans try to keep all the relevant data in a single page
- Maybe chunking could be done on image level (with multimodal models), or even both image and text
- Try preserving semantically similar content
- Indexing
- Raw text often confuses a model
- Don’t embed the raw text, embed references
- For tables, numbers won’t mean much for the embedding model during retrieval, but the caption, references and descriptions of that table are
- Another approach is to do page level chunking, and embedding every sentence and link them all to the page, and during synthesis use the entire page
- The page has a higher chance of being retrieved due to the content it has
- This works nicely with small context embedding models
- Have multiple embeddings to point to the same chunk is a good practice
- A relevant document that might have not been retrieved by one embedding, might be discovered using the other!!
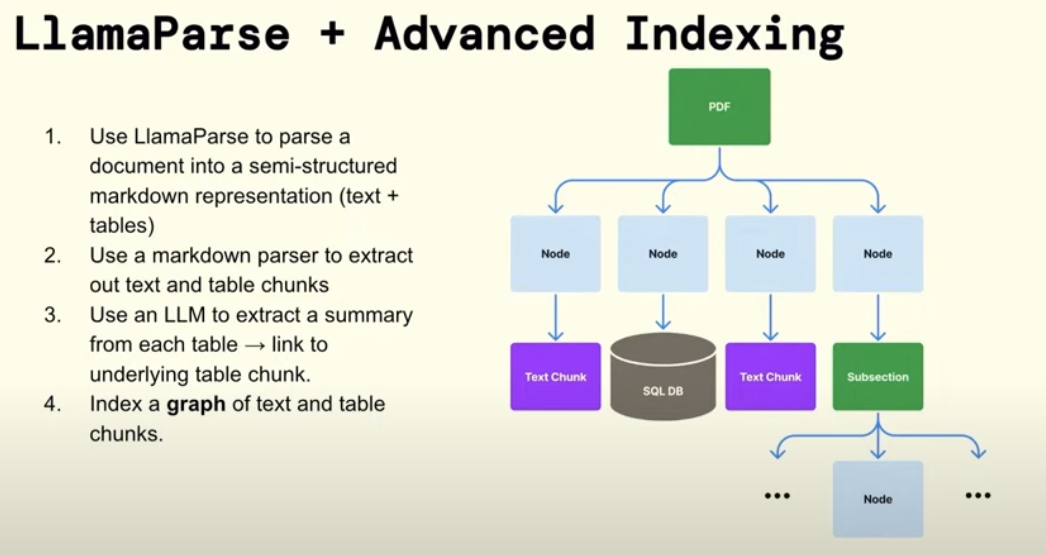
Instead of LlamaParse you can consider open-source versions such as open-parse
Improving Query Complexity
Some queries require more steps than just retrieval:
- Summarizing
- Comparing
- Structured Analysis + Semantic Search
“Tell me about the risk factors of the highest performing rideshare company in the US”
Here the model has to semantically find who is the highest performing etc, and then do an analysis on them
- Multi-part Questions
“Tell me about pro-X arguments in article A, and tell me about the pro-Y arguments in the article B, make a table based on our internal style guide, then generate your own conclusion based on these facts.”
Here the model has to do multiple steps, collect from multiple sources
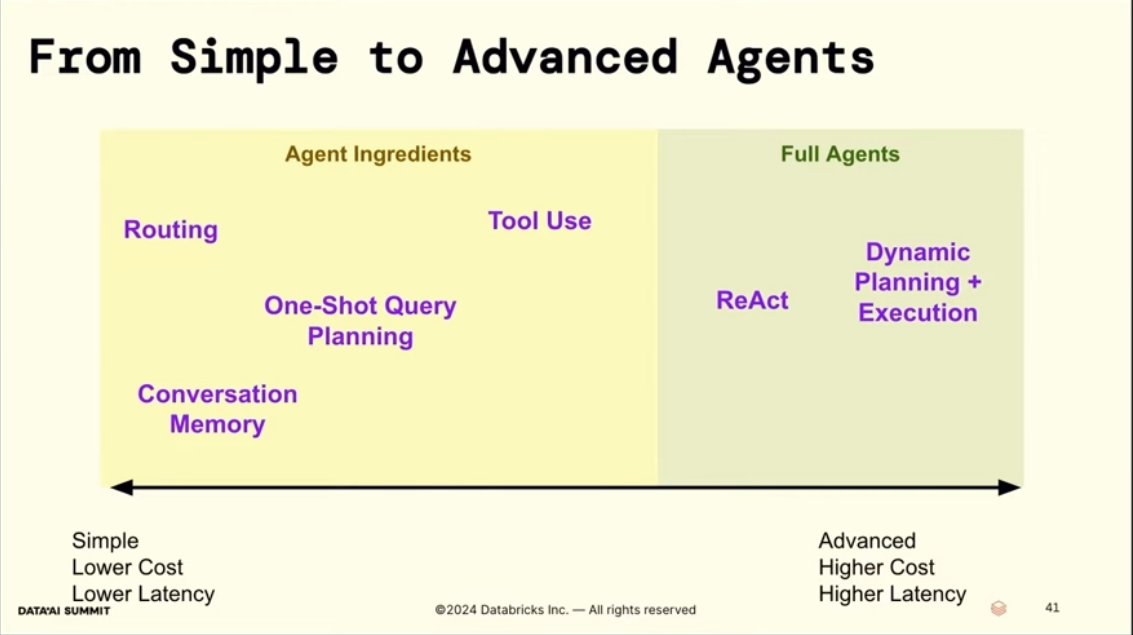
| Naive RAG | Agents |
|---|---|
| single shot | multi-step |
| no query understanding/ planning | query/ task planning layers |
| no usage of tools | tool interface for external interactions 1 |
| no reflection, error correction | reflection |
| no memory (stateless) | memory for personalization |
Agentic system components
Query planning
- Break down a query into parallelizable sub queries
- Each sub-query can be against any set of RAG pipelines
Some strategies include letting an LLM
- break down a query into sub-queries and then parallelize these
- hallucinate an answer and then use that to retrieve
- do a step back, ask a more general question and use that
- chain of thought – break it down into a sequence
Memory
Tool Use
Use an LLM to call an API (now called MCP), function calling
auto-retrival, text-to-sql – let the LLM write a query over metadata (apart from doing a vector search)
Some nice ideas
You can try making tools more flexible (and complex in a way) by
- Dynamically generating tools on the fly or
- Have a generic tool to read a specific file
Agent Reasoning Loops
- Sequential, generate the next step given previous steps (chain-of-thought prompt)
- like ReAct
- DAG-based planning (deterministic), generate a DAG of steps, and replan if steps don’t achieve desired state
- LLM Compiler (Kim et al. 2023)
- Efficient if there are divergent paths that can be parallelized
- Tree-based planning (stochastic), sample multiple future states at step. Run monte-carlo tree search (MCTS) to balance exploration vs exploitation.
- I think this is similar to AlphaEvolve, AlphaGeometry and examples when GPT-o1 was solving competitive programming problems
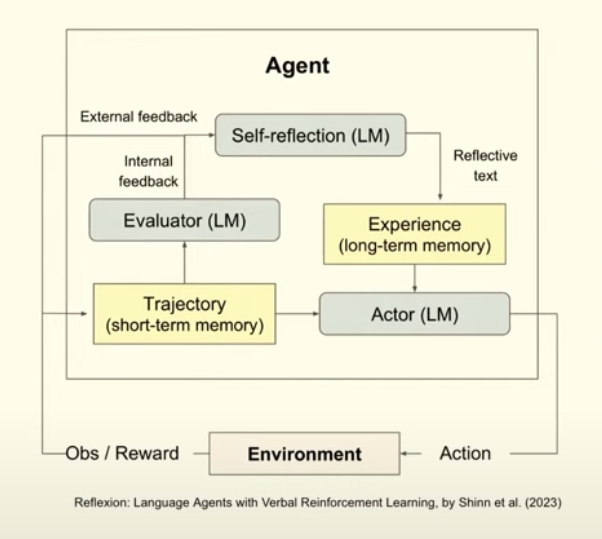
Self-Reflection
Use feedback to improve agent execution and reduce errors
- Human feedback
- LLM feedback
For these tasks a smaller model can be used to evaluate
Footnotes
-
Here, the vector database/data warehouse is treated as yet another tool ↩