Watch the full video from Adam Lucek here.
This video covers how LLMs can be made into a few popular agent flows which give external structure to the agent improving its results.
https://blog.langchain.dev/reflection-agents/
| Method | Paper | Implementation |
|---|---|---|
| Basic Reflection | - | reflection.ipynb |
| Reflexion | Reflexion Paper | reflexion.ipynb |
| LATS | LATs Paper | lats.ipynb |
| Plan-and-Execute | Plan-And-Execute Paper | plan-and-execute.ipynb |
| ReWOO | ReWOO Paper | rewoo.ipynb |
| LLM Compiler | LLMCompiler Paper | llm-compiler.ipynb |
Basic Reflection
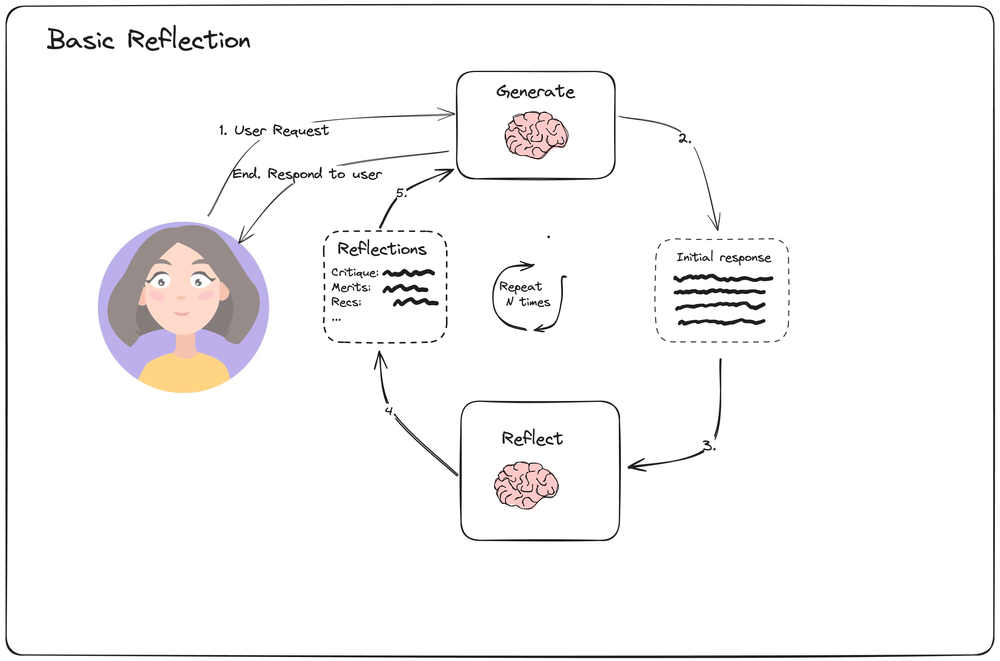 Simple Reflection Loop
Simple Reflection Loop
The setup is straight forward. A user submits a request. An initial response is generated, which is given to a reflection agent. It generates a critique, merits and recommendations and passes them back to the first agent, which generates a new response based on the previous one and the reflections. This loop is repeated N times and the final response is returned to the user.
It regenerates the whole response every stage, hence:
- Token usage is high
- Slow for processing And it has no access to external tools, hence:
- no access to information → makes things up (hallucinating)
Reflexion
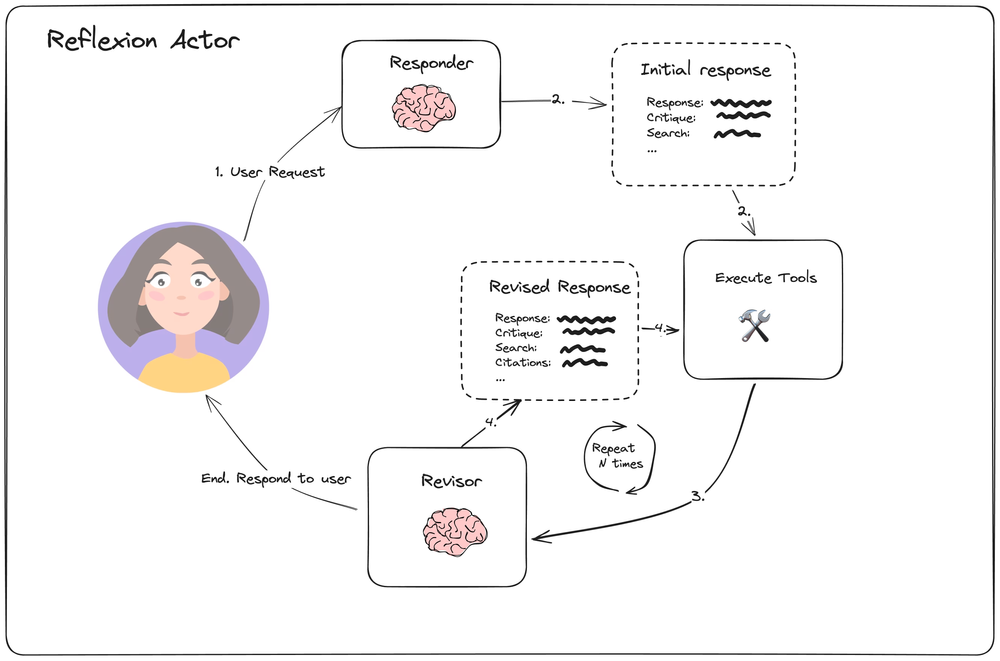 Reflexion Actor Overview
Reflexion Actor Overview
Initially the user submits a request to which a Responder Agent generates an initial response with critiques and search queries after. The queries are executed, and, along side the previous response, passed to the revisor agent as context. It generates a new response, then critiques to it, new search queries to execute and a list of used citations from the previous search result. This loop is repeated N times, and the final response is returned to the user.
In the video, the execution time of this agent was twice as fast. However the forced revision with the long inputs like website texts increase the token spendings. It really varies by the search results from the web.
Language Agent Tree Search
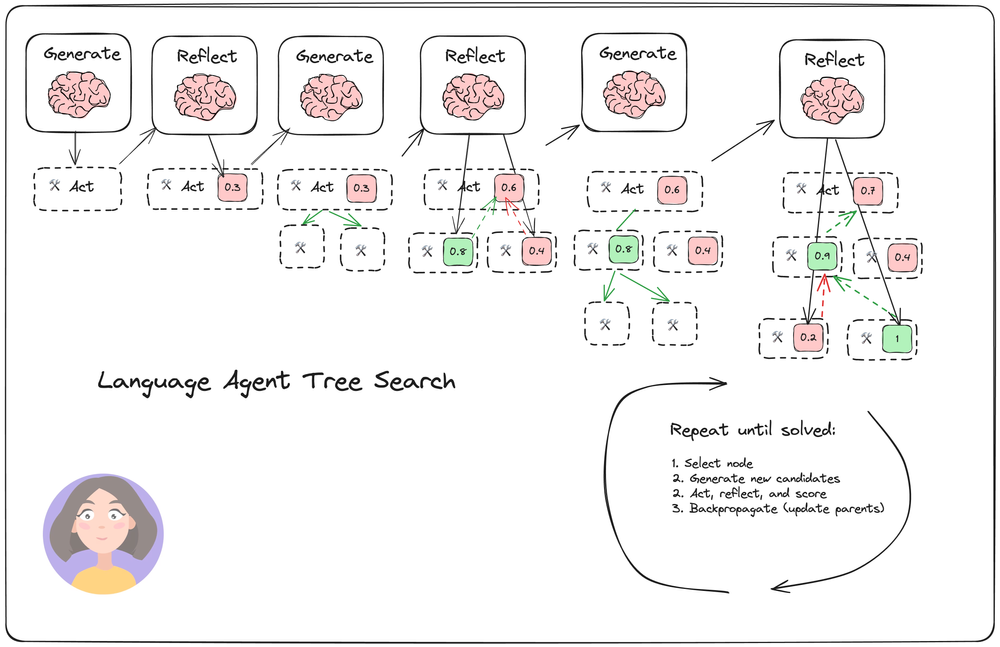 Example of running a Language Agent Tree Search
Example of running a Language Agent Tree Search
Uses Monte-Carlo Tree search approach, to be honest I don’t think I understand this one, but will do my best to explain what I understood.
There are two agents, Generate and Reflect. There is a tree that where actions have been preformed.
Generate agent receives the user query and runs tools to research and then generates a response. Reflect agent afterwards does a reflection writing a critique and a score. Then given both there are N Generations run, and the Reflect agent reflects on and evaluates all of them. The child that has the largest score is selected for further research.
What I suspect is that the score is randomly sample the nodes instead of selecting the largest ones. And if the response is good, the previous node parents’ scores are increased.
In this video it was noted that the agents used for everything: generation, reflection and evaluation. Therefore it could be biased towards itself and the evaluation scores could be inconsistent. My suspicion is that different models need to be used, and for reflection and evaluation a smarted model has to be used.
Plan and Execute
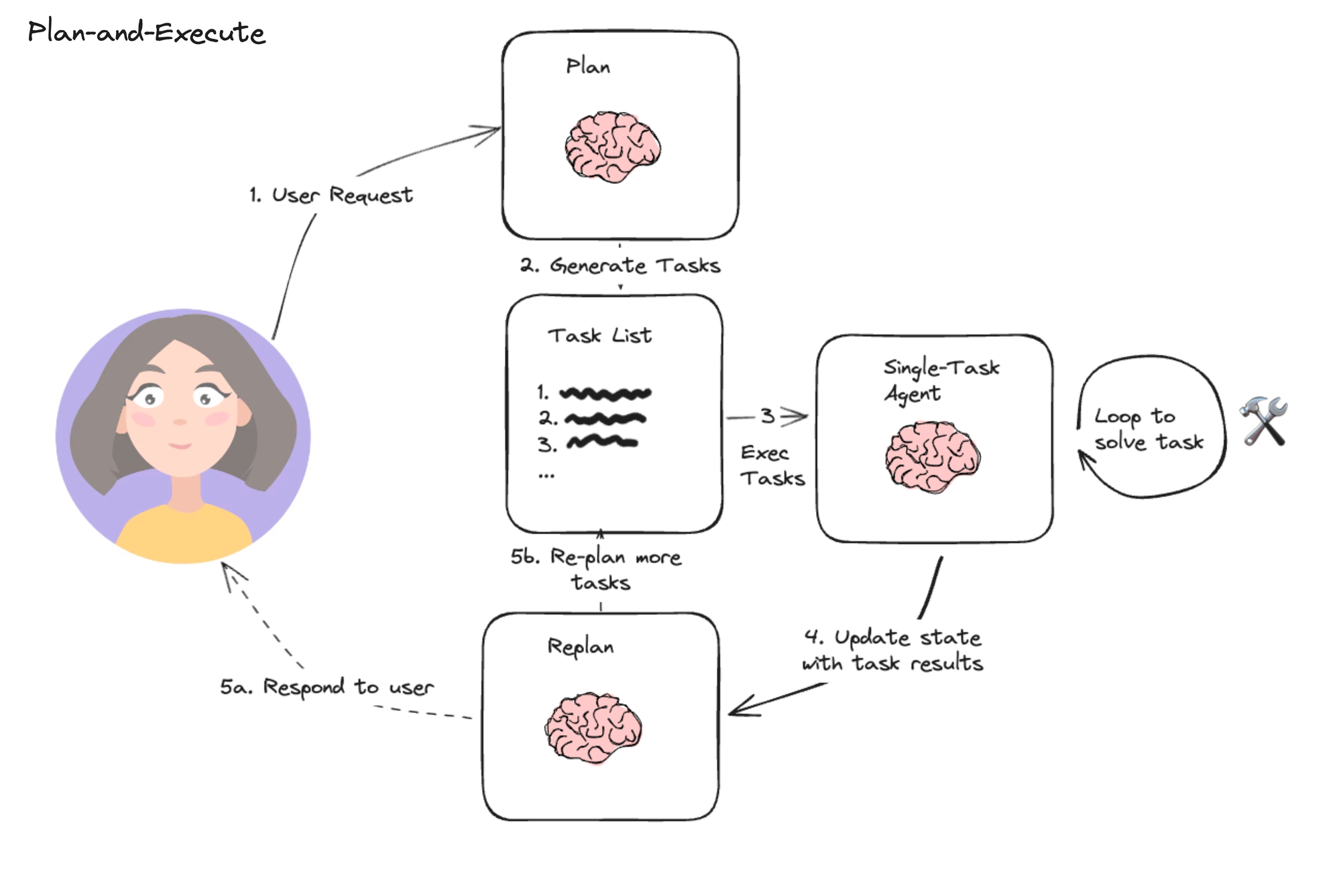
User makes query input, the agent breaks down the query into a plan of multiple steps. This bit I am not sure about, it sounded in the video like we pass the whole plan to the agent, which loops and tries to solve it. Afterwards the query, plan and the result are shown to the replan agent who either chooses to send this result to the user or it replans and makes more tasks.
Another way this could be interpreted, and I think is more plausible is that a single task agent loops over every step. Executes the first one, then the next step with the result of the previous are in the context and the agent solves the second step. And this continues in a loop until all the tasks are done.
I wanted to write the loop out here in the way I understood:
plan = planner_agent.run(user_query) # List[step]
context = [user_query]
for step in plan:
context.append(step)
result = task_agent.run("\n".join(context))
context.append(result)
...It seems like making a plan forces the agent to work better than the reflection because it tries to follow it.
Reasoning without Observation (ReWOO)
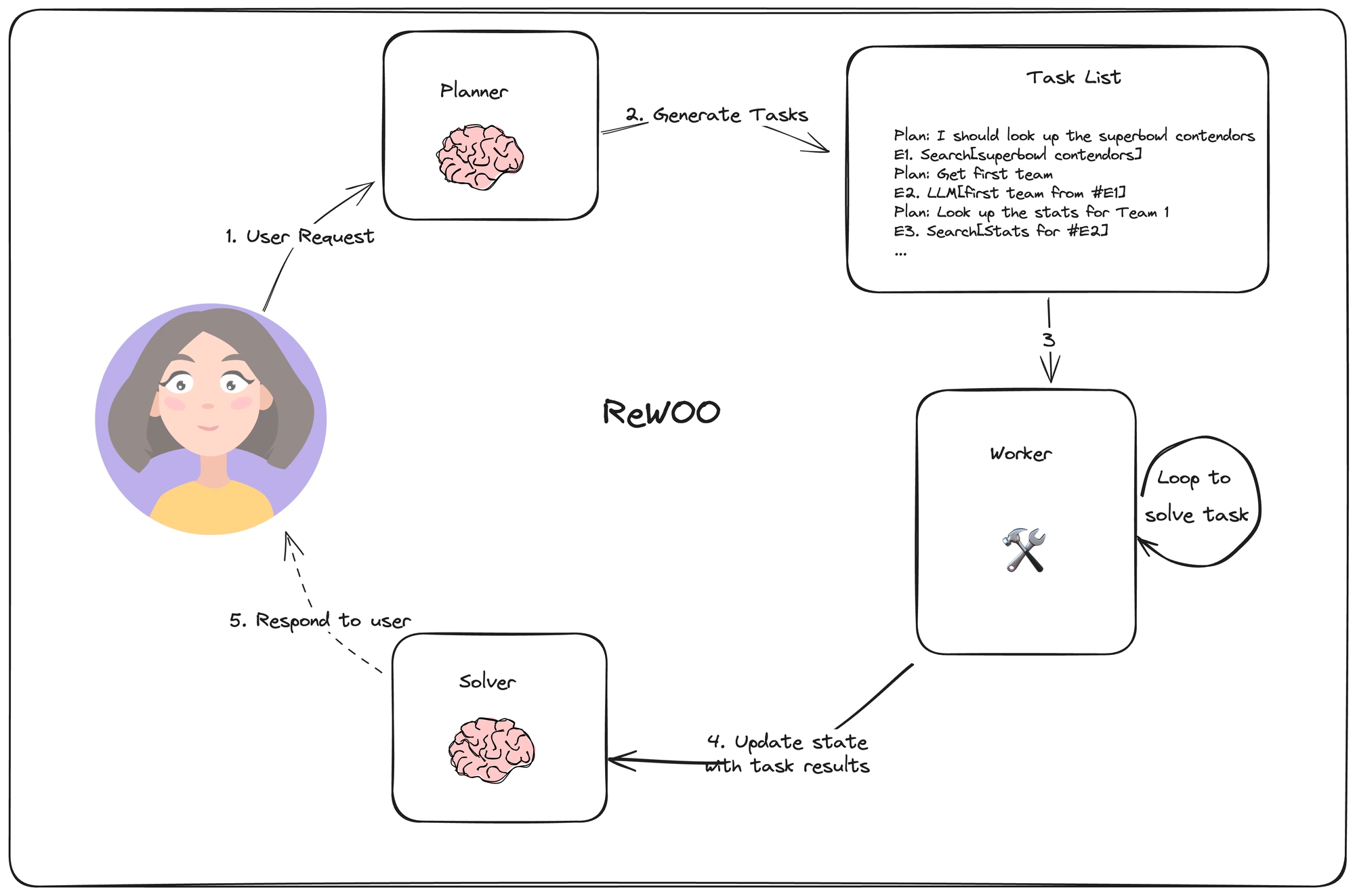
This agent flow is similar to the plan and execute, however now the plan is made with dependent steps. The agent makes a plan, where every output is assigned to a variable and later the agent it able to use the variable to reference the output of a previous step further in the plan. Every step is then executed, which creates a bunch of results. These results are passed to the solver, which generates the final output and that is shown to the user.
This idea tries to optimize on the idea of plan and execute by being able to reference the step result in a plan without knowing what the result of the step is yet.
LLM Compiler
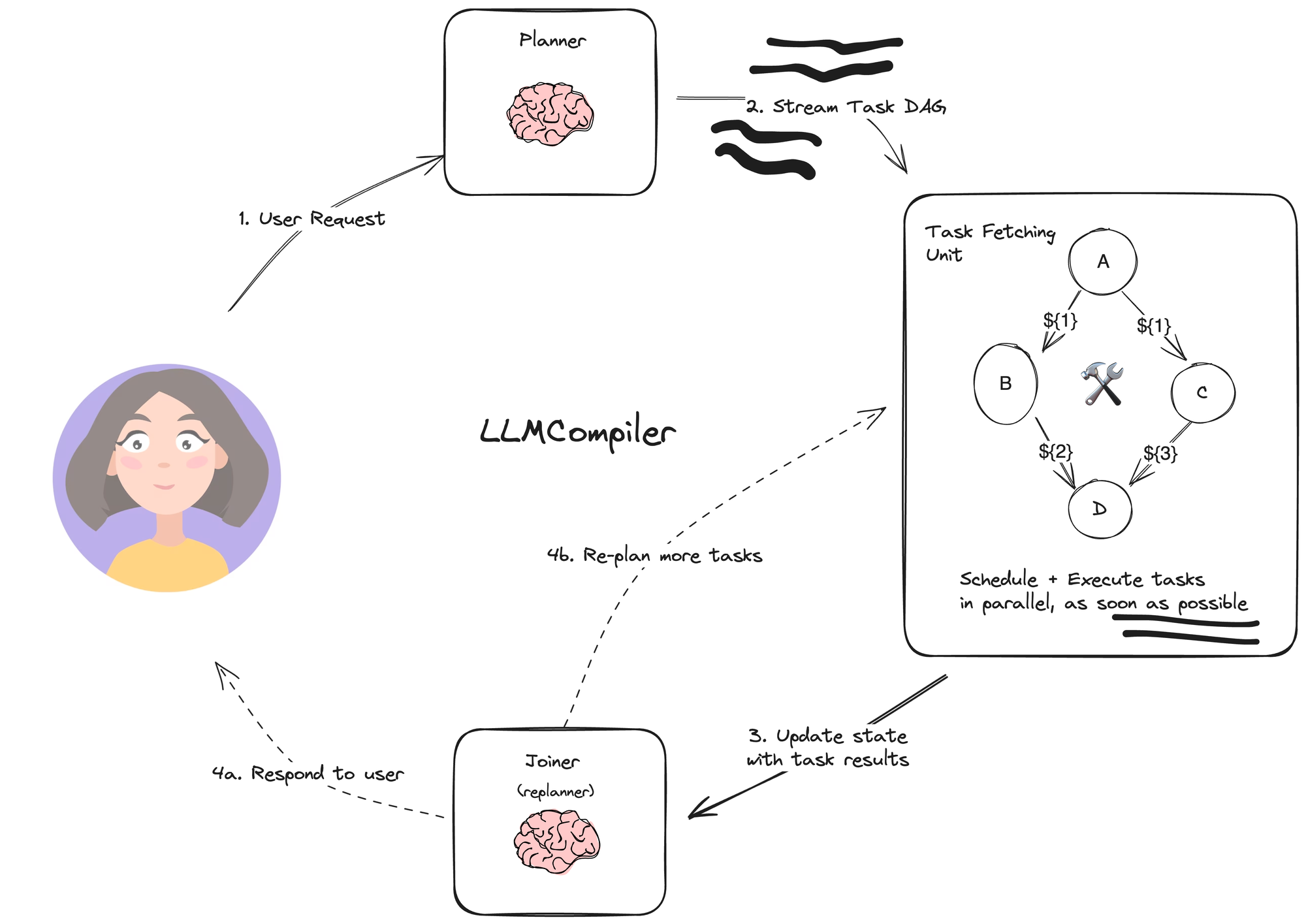
This flow builds up on both of the previous ideas and adds the idea of using a directed acyclic graph to structure the tasks to determine which ones can be done in parallel.
Planner gets a query, and makes a DAG plan out of it. This DAG is then ran over and if steps are independent they can be done as soon as possible because they don’t block each other. Afterwards, these results are given to a joiner which either responds to the user or replans to make more tasks.